尚硅谷大数据技术之数据湖Hudi-1
尚硅谷大数据技术之数据湖Hudi-1
智汇君尚硅谷大数据技术之数据湖Hudi-1
Hudi概述
Hudi简介
1 | 接下来我们先来了解一下什么是hudi。可以简单理解为这么几个单词啊。Hadoop相关的upsurts就是支持插入及更新,并且呢支持一个删除,还有增量的一个处理。那么hudi其实就是咱们经常讲的一个什么数据湖的一个框架。那么官方更愿意称它为一个平台。因为啊它提供了一个平台化的能力,还有很多的功能,并且呢它是支持什么呢牛市的啊,这一点就特别关键的。那么继继续看啊,apache将核心仓库还有数据库的功能直接引入了数据库。也就是说大家使用起来还是应该是比较熟悉的 |
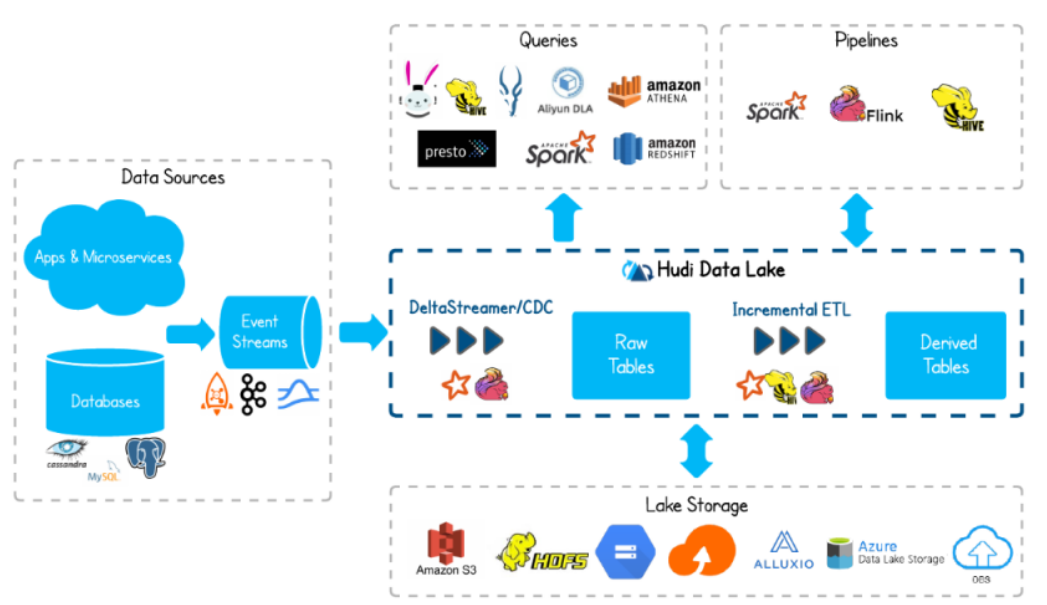
1 | 那我们也可以简单搂一眼,这个架构图也不算架构啊,这是官网放的一张图啊。那么大家可以看到呃属于数据源,就我们的数据来源可能有各种各样的对吧?啊,可能有数据库的像什么mysql,还有其他一些,还有我们的APP产生的,还有微服务产生的一些日志啊等等这些你的埋点信息也可以。那这些呢通过可我们可以统一采集到一个什么呢事件流。什么叫事件流呢?那比如说我们最常用的就是一个什么kafka这种消息队列,还有什么lock ket MQ这些都可以啊,也就是说消息队列这么一种框架。那那我们可数据到了呃消息队列之后,我们可以把它通过采集入湖做一个ETL。那这边可选的工具有特别多啊,可以用一些CDC的工具,可以用hudi提供的这个delta streamer都可以啊,甚至呢我们做的一些Spark跟flink都可以将它采呃数据入湖。那么到了数据湖之后呢,这些数据进来之后啊,它会形成一个什么呢?一特定的hudi表的一些管理之后呢,我们可以基于这个再做一个增量的ETL,还是结合咱们熟悉的一些引擎,像Spark have flink这一些啊进一步的处理,这是进入到湖底之后的操作。 |

发展历史
1 | 接下来我们来了解一下湖底的发展历史。那在2015年的时候啊啊发表过这么一篇文章,是关于增量处理的。它里面阐述了增量处理的一个核心思想还有原则。这个主要区别于咱们传统的全量处理。全量处理呢不仅处理的数据量大,操作重,而且呢效率也没法得到一个很大的提升。那如果我们采用增量处理的方式啊啊首先你每次处理的数据量就小了,并且呢就更及时了啊,这样显然显然是更好的对吧?那么在2016年的时候啊啊,uber也就是美国的这个优步,他创建的湖底这么一个框架,并且呢对他们的内部的数据库还有关联业务提供了一个支持。这个时候还属于他们自个儿用,对吧?那好东西呢那自然要分享嘛。那在2017年的时候,也其实大家可以看到,又经过了一年。那这个优步呢就将hudi给开源了。而且能支撑到百PB的这么一个数据库框架,可以说啊非常强劲。那么这是刚刚开始开源。那么到了2018年呢,这个时候开始吸引了大量的使用者。哎,主要也是这个时候呢呃依赖于云云计算啊,进一步的普及开了。当然在18年的时候,咱们还呃咱们国内应该是用的还不多。那么在2019年呢啊这也算是一个起点呢,成为阿帕奇的一个孵化项目19年并且呢增加了更多的平台组件。也就是说它相关的支撑呃支持的集成的一些组件就更多了啊,而且它内部的一些呃功能组件也更多了啊,总而言之呢啊就是功能越来越多。那么经过一年的时间,他就快速的毕业了,从孵化项目毕业,成为阿帕奇的顶级项目。啊,这也是几个关键的时间点。那这个时候进入了一个快速增长的时间啊,他们的社区啊下载量啊啊采用率啊超过了十倍的一个增长。那么在2021年的时候啊,已经开始支持优步内部啊啊500pb的这么一个数据库了。并且呢一些sql语句啊,还有跟flink的集成啊啊这些都进一步的引入了啊。因为flink也是比较火嘛,那么增加了优化的一些项,所以呢原数据的一些服务啊,还有它的一些缓存等等这些东西。那么到目前呢可以说这个护底在国内是越来越火了啊。这是大概的一个它的发展历史。 |
Hudi特性
1 | 好,另外我们了解一下hudi的一个特性啊,咱们列了几点啊。第一个呢关于它的索引引,它是一个可插拔拔方方式啊。什么叫插插拔呢?就是随随可以插入入,随时可以拔走,对吧?也就是说你可随随时对某张表添加索引,也可以对某张表删除其索引。那么基于这个索引机制呢,就能够帮助我们支持快速的upsert还有delete。这个upsert其实就是插入集更新嘛啊如果不存在就插入,如果存在那就更新。 |
使用场景

1 | 那么了解hudi的,咱们再来聊一聊咱们用户地可以用来做什么事情啊,也就是说我们能够落地的一些使用场景啊,那简单的咱们就总结了这么几个啊,第一个是可以近实时的写入啊,近实时。那么可以减少咱们一些碎片化工具的使用。可以通过CDC工具增量的导入咱们关系型数据库的数据,像MYSQ这种对吧?关系型数据库那还可以呢 |
编译安装
Hudi编译_版本兼容&Maven安装配置
1 | 接下来我们来尝试编译一个hudi。因为hudi并没有提供一个编译好的包,没有提供编译好的二进制包,所以呢需要我们去手动编译。并且呢这中间涉及到很多细节,呃,很多版本的兼容性问题,就一些注意的地方我都会给大家讲,呃,一些坑呢我也给大家踩完了。只要照着我的方式去改相应的pom文件,改相应的源码,就能够很顺利的编译完成来使用了。 |
1 | 那行,那首先咱们得有一个maven,那那maven呢这个资料呢。你可以给比如说我给到你的资料,这个文件夹有放了一些需要的东西啊,比如说这个编译需要的依赖啊,还有maven在这儿啊,我放了一个安装包啊,还有一些其他的东西啊,让你把这个安装包上传到你的服务器上,我这边是已经上传并且安装过了。你上传之后啊,你该tar命令去解压,你正常去解压就行了啊。解压完之后呢,你想改名就改个名啊,无所谓。改完名之后,咱们将maven配到环境变量里,对吧?在/etc/profile里面配一个maven home啊,再拼接到path里面啊,注意后面这个路径写你自己的路径啊,这个写你自个儿的路径,就比如说我这边吧。拉到最后,哎,大家看我这边是添加了一个maven,当然我用的是.3,无所谓啊,一样啊,只要是3.6的应该都没问题。好,配完之后别忘了什么,做一个source让它生效啊,这样就ok了。这样你的maven就安装成功了。但是除了安装之外,咱们还需要做一些额外的配置来加速咱们的依赖下载。因为每maven编译的时候需要下载需要用到的一些依赖架包。那默认它的仓库地址是什么?是国外的呀?那国外如果你没有一些科学上网呃,可能会特别特别慢。所以我们常规做法是什么?是改成阿里的进像仓库地址,这样你国内去他去下的时候就特别快了。那你怎么测试你没有安装成功呢?就执行个命命令呗啊,mvn -v那如果跳出这个maven的信息版本信息,那说明是ok的啊。那CDK的版本我用的是1.8啊,你也要稍微注意一下,至少是1.8了。好,这个是关于maven的安装。那修改的配置呢,比如说哎我来到我的maven路径下面,你解压完应该是有这么几个文件夹的那bin就是命令脚本conf这个配置对吧?我们来到conf文件夹,然后呢这里有一个settings。来settings里面呢,我是配好了,我就告诉你在哪这里你直接搜什么呢?/mirrors镜像对吧?这个默认是注释掉的那下面你自己配一下啊,就比如说。我这边自己你看加一个mirrors标签啊,后面对应有一个结尾啊mirrors那中间这一段注释我就呃是我注释掉了。但是你看我这里加了一个什么阿里的地址是吧?阿里镜像的地址啊,你加上这么一个东西就可以了。那你后面这些你不用管,因为大家知道maven仓库生效,只有其实只有第一个生效,你背的再多也没用啊,中央仓库只会有一个啊。行,这边大家应该都会了,那改完就保存退出就可以了啊。那就按照我给你们的这个添加一个镜像啊。好,那这个就是我们的maven安装及准备。 |
Hudi编译_解决与hadoop3.x的兼容问题
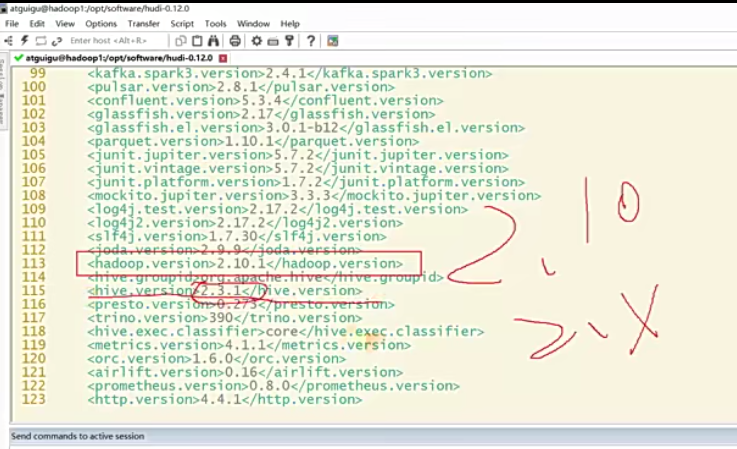
1 | 好,那环境准备好之后呢,咱们可以去将我们的源码包上传到你的服务器上面。那这个源码包你可以从官网下载,也可以从我这边啊我这边放的资料里面放了一个源码包,这个你从官网下就行了啊,这个哪都有,那上传你的服务器应该都会啊。我比如说上传到你的OPT softwere,那在这里呢已经有一个了,对吧?那有了它之后,它是个tar包,我们就解压呗。-ZXVF那杠-C指定你要解压的路径,那我还是放在本路径就好了啊。 |
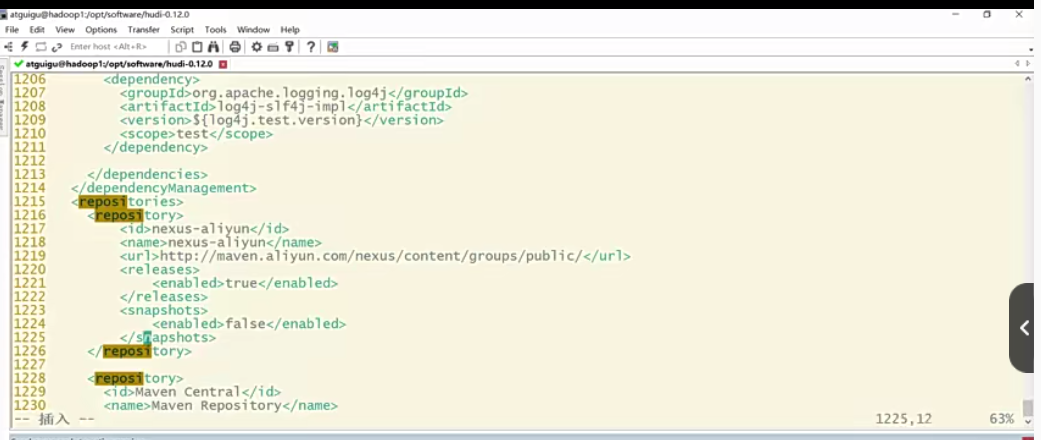
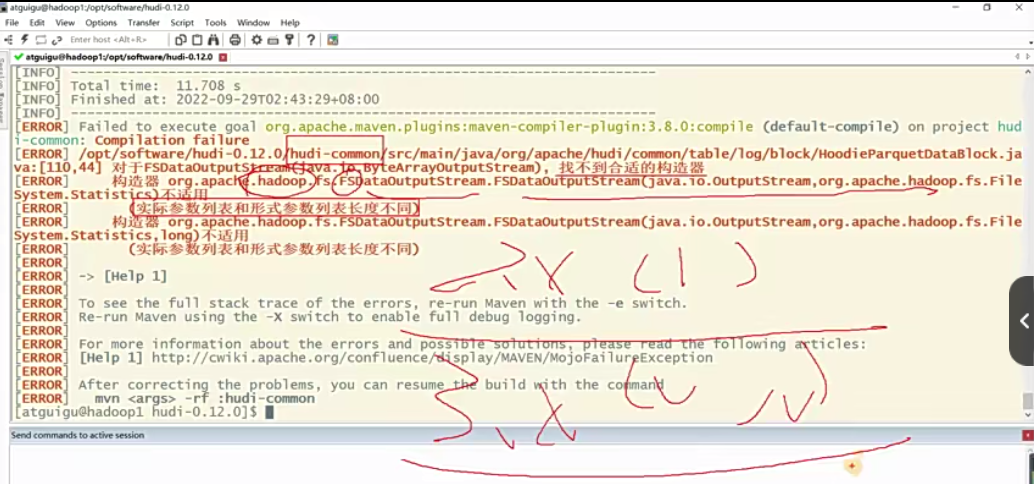
1 | 比如说我先来把拿到执行命令这里指定了各种各样的版本是吧?啊,我需要的版本。好,那这个时候你直接来执行这个maven命令来回车,大家注意看它的报错。啊,稍等一会。好,现在报错了对吧?大家可以看到什么呢?是库迪的COMM门模块啊。然后呢他说找不到合适的构造器,那为什么呢?实际参数列表和形式参数列表长度不同,那么大家注意其实就是这么一个方法啊。就是你看是hadoop相关的,然后呢是FS相关的。它这里面传参2系列它是一个参数,三系列它是两个参数。这个就是它的一个调用的api的兼容性问题。那这个地方要解决起来很简单啊啊,我们呃由于第二个参数我们是没什么用的啊,或者说对我们来讲没有实际意义,所以你给他传个null就好了。哎,所以呢你在这个地方要修改它啊。 |
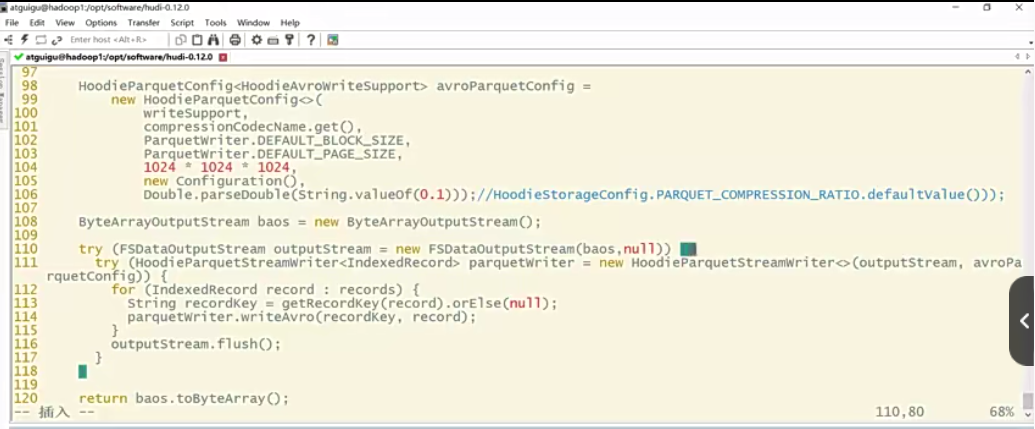
1 | 那第三个,我刚才讲到的这个报错,这个怎么解决呢?他报哪个类,你就修改哪个类就行了啊,就是这个类嘛,这是一个java文件啊,张好写的第110行第44个字符,对吧?所以你直接拷贝这个类内名啊,vim这个类名我直接粘贴,哎,回车我显示一下行数。呃,大概是110行对吧?那我们看其实就这一行对吧,是不是FS的这个输出流的这么一个构造。这个是2.10版本或者说二系列哈。那现在我们用的是三,那我就在构造第二个参数给他。全都是细节啊,哎你加个null就行了。呃,如果你想研究一下这个参数的意义,你自己去对比吧,这里我们就先不展开了啊。现在目前对我们来说是没意义的,我传个null就行。好,保存退出。这样的话刚才这个报错,哎,也就是这个报错就不会再出现了啊,这是解决跟hadoop版本兼容的一个问题,好吧。 |
Hudi编译_手动安装需要的kafka依赖
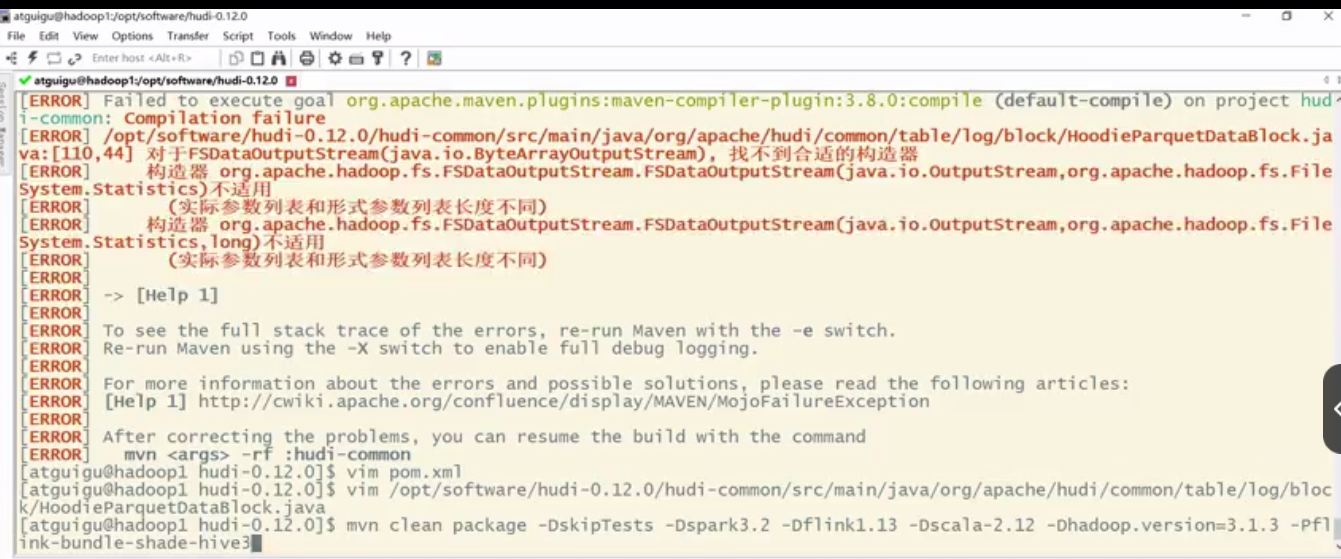
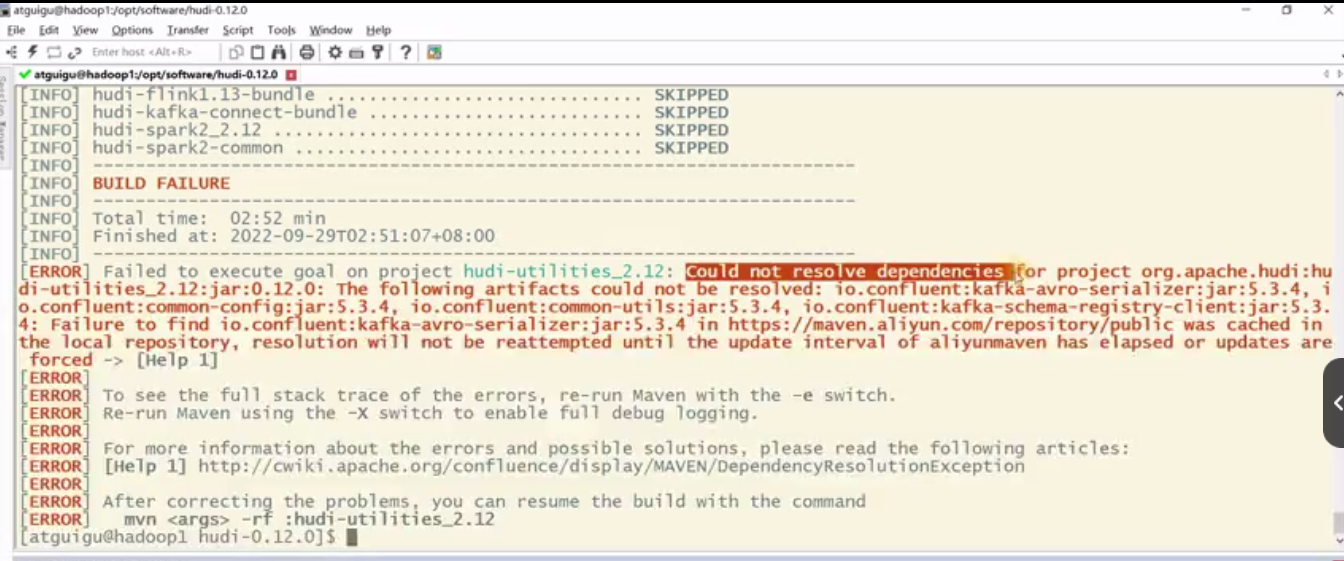
1 | 那解决完了跟hadoop的依赖问题,那还得再来解决一个跟kafka的依赖问题。啊,为什么呢?因为我们在编译过程中有一个栈是hudi的工具栈,在编译这个栈的时候,它需要用到kafka的一些依赖,对吧,像kafka-avro序列化器呀,啊等等这些东西,呃,比如说我刚才的编译命令再执行一遍吧,那个hadoop已经解决完了,应不会再报那个错了,但是他会报其他的错啊,我还是执行这个命令给大家看一下啊。那让他跑着我们继续讲啊,那这个这些依赖你在maven中央仓库是下不到,或者在各个地方下不到,呃,因为这个是已经要在confluent里面去下,我们需要手动下载,并且呢,手动安装到你的本地maven仓库啊,那这个东西怎么下呢?呃,我已经把链接给你了,去confluent官网去下就行,他报错需要的版本是5.3.4,那你就下5.3.4啊 |
Hudi编译_解决Spark写入Hudi的兼容性问题
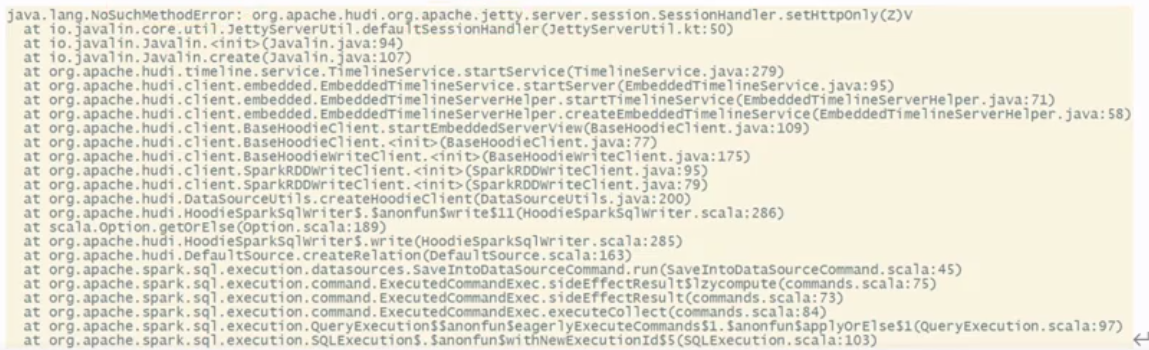
1 | 再接下来呢就是要还有一个跟Spark的问题。这个问题呢在你编译的过程中并不会暴露出来,但是在你使用的时候才会出问题。就如果你我看我没有把报错写上来啊,看这里就好,我就不再演示了啊。也就是说如果你没有解决我这个事儿的话,你在编译完成之后,你用spack来操作hudi表啊,你能进去。但是呢你再往一张hudi表插入数据的时候,你执行一个insert,它会报错。哎,他说找不到一个方法,什么方法呢?什么apache的jetty,这个相关的错那这个东西呢是为什么呢?我跟大家讲一下啊,因为它这边呢是Spark模块,它会用到一些hive的依赖。那由于hive的依赖,咱们已经改成了3.1.2,对不对?那他本身携带了jetty?那hudi它本身的COMM模块,呃,它也有一个jetty,说白了就是什么把就jetty的依赖冲突问题,所以咱们这个问题要手动去解决一下啊,解决一下嗯,让大家可以看到呃。hive携带的是0.9.3,hudi本身用的是0.9.4,啊,存在一个依赖冲突。所以这个时候我们要去修改一个依赖啊,排除低版本的阶梯。 |
1 | 那在后面我们加一个排除啊,你直接拷贝就行了啊。这是我已经改过了,哎,他已经排除了一个了,那么直接添加这几个就行,添加这三个啊。在这里添加这三个还没完呢,这只是第一个依赖要改。 |
Hudi编译_执行编译命令&jar包位置
1 | 那最后就剩一步了,就是执行编译就可以,我们先回退到这个解压的跟路径下面啊,hudi 0.12.0,好,在这大家注意啊,要在这里执行啊,在这个地方执行mvn编译就可以了,那么这边大家注意看一下我的命令。我的命令指定了啥呢?你看mvn,呃,清理clean,然后呢,打包package跳过测试-DskipTests,那后面是关键啊,同学们首先-D,我指定的什么Spark的版本-Dspark3.2,因为我前面看release也跟大家讲了,它是可以支持什么,诶我2.4的Spark 3.1的Spark 3.2的Spark,那这边你不指定默认就是3啊,默认就是3,呃,那我们这边最好是指定具体版本3.2,另外flink是不是支持13 14都支持啊,对吧?那你也要稍微指定一下你具体哪个版本,那我用的是1.13flink,大家注意格式不能变啊,就按我这个格式写。第还有一个呢,就是flink也好,Spark也好,都有不同的scala版本,对吧?啊,那这边你也要指定一下scla版本,我用2.12,大家注意格式是这么写啊,中间得有一个横杠啊,另外呢,就是当然我这边是多此一举啊,就指定哈,hadoop跟hive我已经改完了对吧,但是后面这个最好还是加一下啊,指定我编译集成。这是HAVE3啊,行,另外指定一个哈杜版本,总而言之言的,总之你就照着我这个来改就好了,因为他这这个命令有很多,还有各种简写缩写对吧,比如说你可以只写一个SPARK3,那它默认是用哪一个版本,这啊那的啊,你就指定具体的就好了,好吧,这个东西如果你想看我提一嘴啊,他在这里有一个read me呀,没了吗?好大写的,在这里他有简单的说了几句啊,你可以自己看看啊,一些编译环境要求,比如说JAVA8以上的得有记,呃,对main问得大于3.3.1对吧?啊,然后可以指定Spark怎么指定。对对,这边都我告诉你,你不同的写法,它指定的还有兼容的版本是不一样的啊,你自己在这边找一找啊。那包括弗link也有好吧啊,弗link也一样,你不指定斯GALA版本,它默认就用的2.11啊,这个是大家要注意的地方啊呃,最好的方式就像我一样,所有的东西我都给你指定好了,不啰嗦了,直接把这条命令怎么样拿过来,然后呢,在这个跟路径下面执行,哎,拷贝粘贴回车,接下来就是等待就可以了啊。如果你按照我的步骤,前面都修改完了,接下来就不会报错了啊,那我先停一下,等他编译完。 |
核心概念
基本概念
时间轴TimeLine

instant
1 | 我们了解一个护底,那么它特有的一些概念,我们也要首先了解,那首先呢,我们看一下三点一基本概念。那第一个呢,就是时间轴。那这个时间轴怎么理解呢?其实就是什么?这你看看这个图,这是不是一个时间线对吧?那么中间的每一个点,上面的每一个点都是一个时刻,对吧?那其实就是什么呢?它这个时间轴在不同的时间点上都记录了我们做的每一种操作。那这个怎么理解,拿我们生活中的例子来比喻啊,比如说你一个人在一天当中,你对他做了一个记录,那比如说啊,早上呃,6点他起床刷牙洗脸,诶,你记录一下,比如说你拿个小本子把它记下来,那再者说呢,啊,到了6点半啊,他蹲了个坑啊。那你记录一下,那再比如说7点。他吃完早饭出门了啊,出门啊,然后怎么样怎么样,就按照这个时间的发展,在每一个关键的时刻呀,啊,每一个动作,每一个行为,你都将它记录下来,那记录下来有什么用呢?你是不是可以方便去回看呢?比如说到了晚上,呃,8点了,你想回忆一下,诶早上8点钟我在做什么,你是不是看一下你这个记录就可以了,那同样的道理啊,啊hudi里面的时间轴就是这个意思。它就是一个时间线啊。随着时间推移的一个时间线,那你的每一次操作他都记录了下来。这个就是它的一个时间线啊,时间轴啊,也有的翻译为时间线,还有呢,就比如说我们一些博物馆,不是有一些历史类的博物馆,那它可能会设计一个走廊或者一个展厅是什么呢?呃。每一年的重大事件,比如说1921年这边发生了什么什么事件,再往下一个。资料图片,它是比如说19啊多少年,1931年啊,然后这边有什么重大事件,在1932年什么重大事件,三三年什么重大事件,那这个也像是一个时间轴啊,我们走过这个回廊,就像穿越了历史时空一样。好,那刚才是简单来理解这个时间轴的概念 |
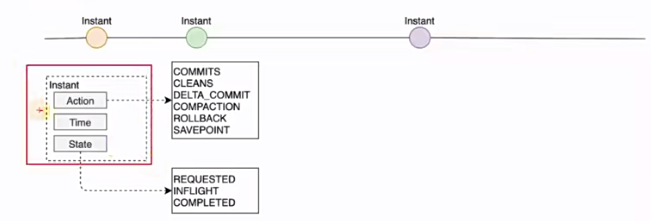

1 | 那这个instant有这么几个组成部分啊,大家看这个图instant,一个instant有三个部分,第一个你做的动作啊,就像刚才例子啊,你6点半你的动作是什么啊,是起床洗漱对吧?这就是咱们记录下来的action。另外一个是不是时间点呢?time也就是说是什么时候发生的啊,6点半这个就是这个太state就是一个状态,这个是属于呃 |
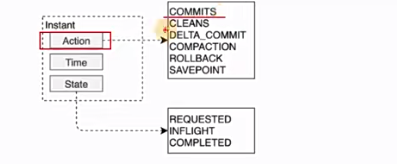
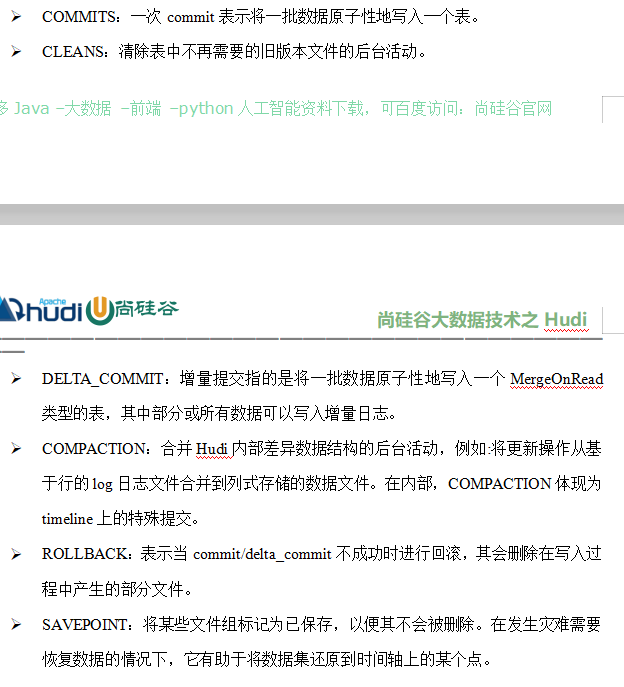
1 | 那么具体来看一下啊,这个action最hudi当中有哪一些东西啊,那看图更直观一点啊,你看有commit,就是提交对吧,还有清理cleans,还有增量提交delta commit,还有这个compassion,也就是翻译成压缩或者合并啊,那还有一个什么回滚rollback,保存点savepoint啊,那这个我们先留一个简单的印象啊,但大家知道这些动作。 |
时间概念
1 | 好,那最后一个呢,我想强调的是一个时间的概念。时间的概念,这边的时间我们要区分两种概念,第一个就是hudi去做提交,也就写入的这个时间,或者说咱们可以理解为数据到达湖底的时间,因为你commit数据不就进湖底了吗?对吧?Commit不就写入湖底了吗?啊,那这个时候其实也就是到达湖底的时间是吧?那么大家知道数据本身是不是也可能携带时间啊,所以另外一个东西叫event time |
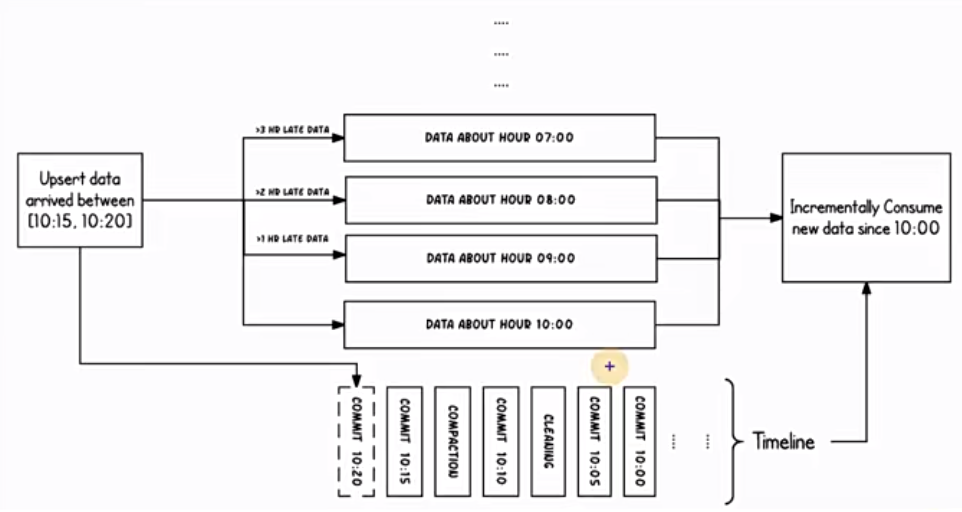
1 | 那么看一下hudi对于这种事是怎么处理的啊,那么看上面这张图就可以,呃,这边采用了还你看啊,也是按照小时作为分区字段,也就是说一个小时是一个分区,对应一个目录,大家用hive的那个分区来理解就可以了啊,那么从10点开始陆续产生各种commit。啊,从10点开始,那么10:20的时候,来了一条9点的数据,意思就是这条数据是9点产生的,但是到了10:20啊,他才commit到咱们的hudi表里面去啊,那这个时候根据事件时间这条数据啊。啊,我们这个分区字段可以用数据的它本身的时间来做分区嘛,对吧,你是9点,那你自然应该落到什么,写入到9点的分区,这个是没问题的,也就是说它能够落入对应的分区里面去,那这问关键就在于那我在读取hudi表数据的时候,我在消费的时候,呃,怎么拿到这条迟到的数据,这个是不是算迟到啊,我时间已经10:20了,但是9点的数据刚来。啊,那这个也没事,我们只需要按照正常的这个到达时间去过滤就可以了,这条数据我们我们增量去消费的时候,比如说我是消费10点钟以后提交的数据,Commit过来的数据,那么9点的这条数据它是10:20才提交过来,那么我们也是能够消费到。啊,说这么多就是想表达一点,呃。我们不用去担心迟到数据消费不到,第二个事呢,迟到的数据,嗯,他该落入哪个分区,还是能够落入哪个分区,当然前提是咱们这个用法是对的啊。啊,这个是一个时间概念,应该也好理解啊,总结起来就是这张图啊,一个时间线啊,每一个时刻都记录了一些事,那每一个记录当中分为什么时间,还有做了什么事啊,现在处于什么状态啊,这么三个东西。 |









